mpw-emu: Emulating 1998-Vintage Mac Compilers
Wherein I run classic Mac command-line development tools on a modern computer, using Rust, Unicorn Engine and a pile of hacks.
Background
I've been poking on-and-off at the classic Mac version of Yoot Tower, an underrated simulation game. I've wanted to try my hand at decompiling it, but to do that, I need a comparable compiler.
I won't talk too much about the game here because I would like to write another post about it at some point, but to cut a long story short, it appears to be compiled using Metrowerks CodeWarrior Pro 1 and the Metrowerks PowerPlant library from Pro 2.
These tools run okay in an emulated Mac OS environment using QEMU (except for the debugger), but it's not the most pleasant experience.
Getting files in and out of QEMU requires faffing about with networking, and editing code in an IDE from 1998 is cute but rather impractical for somebody used to VSCode and Neovim. There's also a strange issue where the mouse cursor occasionally jumps to the corner of the screen. There's fixes and workarounds for these issues, but it would be a lot nicer if I could just use my standard text editor outside the emulator.
With GameCube/Wii nonsense, I can run the command-line CodeWarrior compiler on a modern system very easily - it's a 32-bit Windows executable that runs natively under practically any Windows, or in WINE on Linux and Mac.
Unfortunately, the same isn't true here. Macintosh Garden has a Windows disc image for CW Pro 1 which supports cross-compilation, but Metrowerks only saw fit to support building code for 68K Macs from it, and Yoot Tower is PowerPC.
There was still hope, though. The CodeWarrior Reference CD contained documentation for a command-line compiler, which I spent an embarrassingly long time trying to find. It turns out it's included as part of their MPW package.
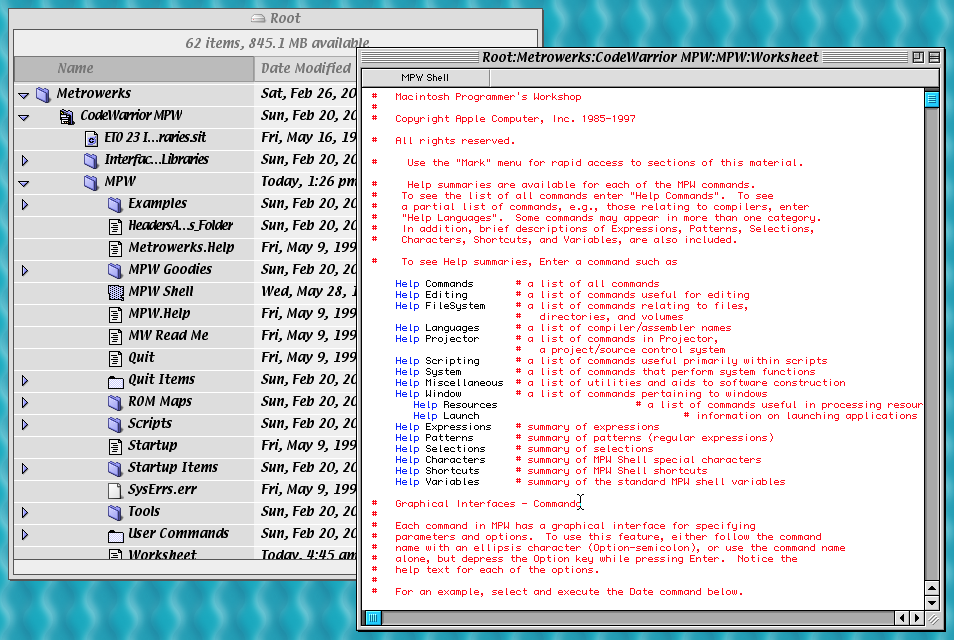
MPW is the Macintosh Programmer's Workshop, a rather strange tool that represents 80s Apple's take on a combined IDE and shell. You get a persistent document you can enter commands into, and you execute one by placing the cursor on the line and pressing ⌘-Enter - with the output being added to the document underneath.
All of the tools I needed could be accessed via MPW. Could I get these to run externally somehow?
There's an existing project on GitHub (ksherlock/mpw) which does this, but only for 68K executables, so that wouldn't do the job for me. It's definitely possible, though... am I masochistic enough to try and implement my own? (Spoiler: yes)
I've never touched any form of classic Mac development before, so this is a bit of an adventure. Here's an introduction to the platform just so you know what we're dealing with.
Classic Mac OS
When you think of a Mac today, what comes to mind is probably Mac OS X macOS - a Unix-like system built on top of the XNU kernel. It's got lots of proprietary Apple libraries on top of it, fancy graphics, and various quirks, but it's still POSIX-compliant.
You could be forgiven for looking at a screenshot of Mac OS 9 and thinking it's broadly the same. While the user interface has many similarities, that's pretty much where it ends.
The first Mac had a Motorola 68000 microprocessor, 128KB of RAM and a basic (by our current standards) operating system. The screen was black and white (you didn't even get shades of grey), and you could only run one app at a time, but it was still pretty cool. This was almost two years before the first Windows was released!
The OS slowly evolved throughout the years, gaining features like networking, multitasking, system extensions and virtual memory. We take it all for granted today, but this probably seemed revolutionary at the time.
The System 7 series in the 1990s also saw Apple's first CPU architecture transition, where they moved the Mac from Motorola's 68K chips to PowerPC, as well as including an emulator that allowed 68K executables to run.
If you think this stuff is interesting, Folklore.org has a ton of fun stories and anecdotes about the development of the original Mac and its operating system. I've wasted far too much time reading them :p
Classic Mac OS was wildly different from its competitors, which was both an advantage and a disadvantage. We struggle today with the differences between Windows and Unix-likes (a recurring issue with cross-platform development tools), such as path separators, but even these aren't quite as stark as the differences between the classic Mac and everything else.
File Management
I'd say this is probably the biggest thing that separates the classic Mac from... everything else. Graphical file managers on Windows and other Unix-likes were built to display a hierarchical file system that already existed. On the Mac, the GUI was designed first, and then the file system was built under it.
Take a hypothetical file on a typical Windows 95 system called passport.pdf. This is essentially what the OS knows about the file...
- It's called
passport.pdf, so it's probably a PDF - It exists within
C:\My Documents\Important - It contains a stream of bytes, which may or may not be a PDF ¯\_(ツ)_/¯
- It has timestamps for when it was created, modified and last accessed
- It has attributes (read-only, hidden, system)
Mac OS keeps track of a boatload of extra stuff. This is what you could expect from a similar breakdown of a Mac file.
- It's called
Passport, and exists inside directory ID 37- If you dig through the tree, you could get the path
Macintosh HD:Documents:Important:Passport - The Mac OS APIs mostly avoid using paths, preferring to identify files by their name and parent directory ID
- If you dig through the tree, you could get the path
- Its type code is
PDF, and its creator code isCAR0 - Its data fork contains a stream of bytes, which is probably a PDF
- Its resource fork is empty (more on this later)
- It has timestamps for when it was created and modified
- It has lots of attributes (locked, ...)
- It has Finder-specific data: visual position in its parent directory, user-specified tags, and more
Very different. Not necessarily better or worse in every aspect, but of course this is a bit of a problem for interoperability.
Extensions vs. Type/Creator Codes
Identifying files has been a perennial issue in computing. MS-DOS used three-letter file extensions, and these stayed around into Windows. If I take a photo and rename it from dog.jpg to dog.exe, Windows will happily try to execute it, and then tell me it's not a valid application. If I rename it to dog.xlsx, then it'll try to open Excel, which will of course have no idea what to do.
The Mac went for codes instead, which are stored in the file system metadata and cannot be easily changed. (It's possible of course, but not through the standard Finder interface.)
Here's some I found on my emulator, for a rough idea about how they were used...
| File | Name in Finder | Type | Creator |
|---|---|---|---|
| Acrobat Reader executable | application program | APPL |
CAR0 |
| Acrobat™ Reader 4.0 document | PDF |
CAR0 |
|
| Readme text file | SimpleText text document | TEXT |
ttxt |
| C++ file created in CodeWarrior | CodeWarrior text file | TEXT |
CWIE |
| Object file compiled by CodeWarrior | CodeWarrior library | MPLF |
CWIE |
| Finder executable | file | FNDR |
MACS |
| Chicago fonts | font suitcase | FFIL |
DMOV |
| QuickTime movie | QuickTime Player document | MooV |
TVOD |
| Yoot Tower save game | Yoot Tower document | T2Dc |
PPT2 |
| Yoot Tower plugin | Yoot Tower document | MvPI |
PPT2 |
Note that different kinds of text files share the same TEXT type, but have a different creator, so the OS knows which application they're associated with.
CodeWarrior will refuse to compile C++ code that's in a file without the TEXT type, but it doesn't care about the creator, so it's okay with me writing C++ in SimpleText.
Resources
Mac OS has a rather intricate subsystem for storing resources alongside files, in what's called the resource fork. This is basically a B-side to a file, and uses a standard container format.
The OS gives you tools for reading and writing resources. There's various standard resource types that store all sorts of things (icons, cursors, pictures, sounds, string tables, window layouts, ...) but you can also create your own types with custom formats.
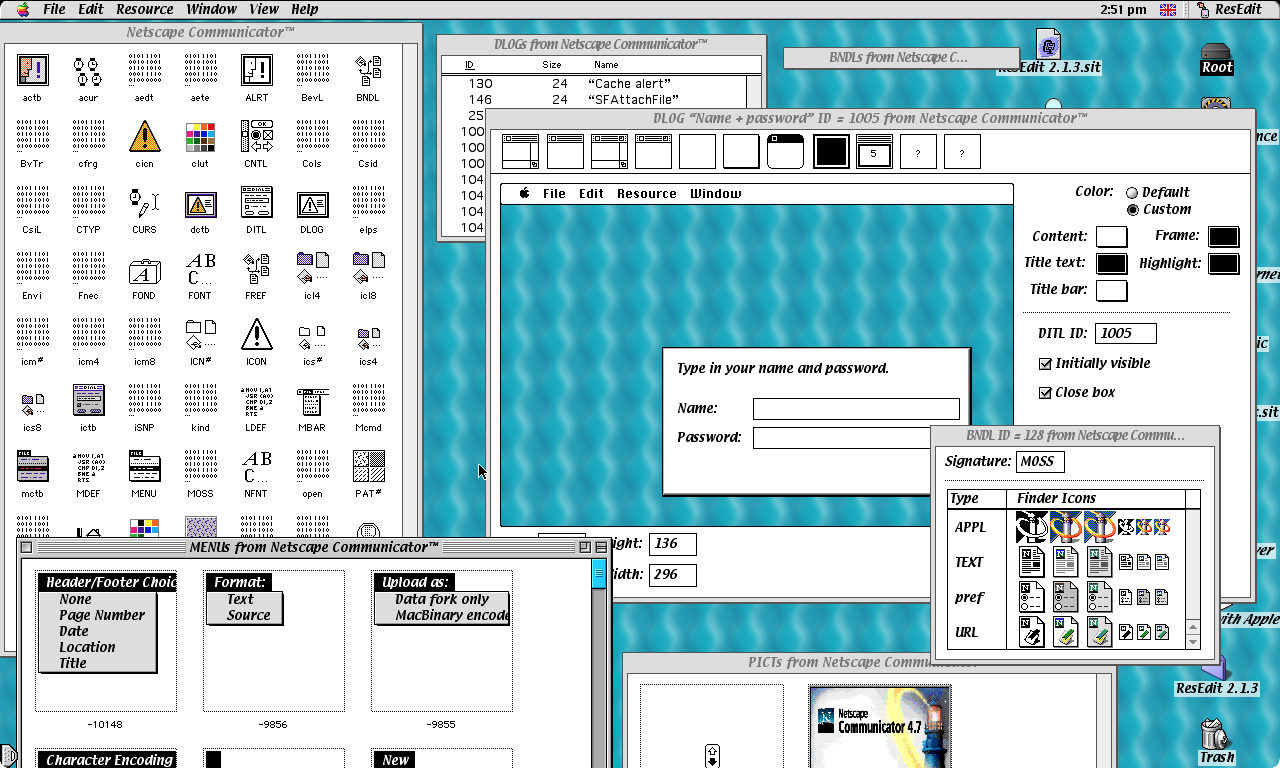
Instead of trying to explain them, I'll just show you a screenshot from ResEdit (Apple's graphical tool for viewing + editing resources).
Here you can see some resources from DLOG (dialog box templates), MENU (menus), PICT (bitmap images) and BNDL (icons used for files in the Finder).
Note how the BNDL resource, at the bottom right, maps specific icons to specific type IDs. This is what determines whether a file created by Netscape (creator code MOSS) looks like a webpage, a preference file, a URL, or something else altogether. It all comes together!
Since resources can be modified on-the-fly, Apple even encourages applications to use them for storing user data like preferences. Not every app does this, but this means that you can actually have a single file which is a self-contained unit and can be taken to another machine easily.
Or, well, it's easy if you only interact with other Macs...
Entering and Leaving the Mac World
How do you take one of these files elsewhere? A PDF or a text file is pretty straightforward - they don't use resources. But say I want to upload my cool new Mac app to my Linux web server - what now?
There were a few different options for this back in the day, like MacBinary and BinHex. You may have seen old Mac files with the .hqx extension around - that's BinHex!
These are just schemes that take the two forks and relevant metadata and combine them into a single blob which can be passed around on non-Mac systems easily.
If I upload a file from Internet Explorer 5 for Mac, the server will receive a MacBinary formatted blob. Likewise, if I download a MacBinary file, it will automatically be decoded.
The resource fork isn't really used by post-OS X Mac software, but the functionality lives around - and the modern macOS Finder still supports metadata, so that needs to go somewhere.
AppleDouble lives on today, which is Apple's own portability implementation that stores the resource fork + metadata in a separate file. You have probably seen these without realising, in the form of files that have names starting in ._ and .DS_Store - a phenomenon so hateful that someone once riffed on it by making a Twitter bot that automatically replied to any tweet mentioning .DS_Store with the word .DS_Store and a file emoji.
Pascal Strings
Another fun quirk about programming for the classic Mac is that the libraries were all created to target Pascal, with C/C++ as a second-class citizen. This is most obvious when dealing with strings.
C does not have first-class strings, and instead uses arrays of characters where the string is terminated by a null character (zero). Pascal actually has strings, but they're encoded differently: the first byte represents the amount of characters in the string.
| String | C | Pascal |
|---|---|---|
| "Hi" | 48 69 00 |
02 48 69 |
| "Hey" | 48 65 79 00 |
03 48 65 79 |
| "Hola" | 48 6F 6C 61 00 |
04 48 6F 6C 61 |
Compilers for the Mac try to paper over these differences by letting you enter Pascal string literals using special syntax ("\pHey" generates a string containing the appropriate length prefix), but you still have to be mindful of it while writing code.
Memory Management
Memory is a scarce resource on old machines. Mac OS has a fairly complex memory manager to try and get the most out of it. There are two main ways to allocate memory.
Pointers
NewPtr is analogous to standard C's malloc, and simply gives you a block of memory you can work with. You can free it using DisposePtr, or resize it using SetPtrSize. (Unlike C's realloc, this will only work if there's enough space to resize the block - it will not reallocate it elsewhere for you.)
Handles
NewHandle is the entry point to the Mac's relocatable memory blocks, and that's where things get fun. You are given a pointer to a pointer to a memory block. This allows the OS to move the blocks around to minimise fragmentation of the heap.
Say you call NewHandle(1024), requesting a kilobyte of memory. You might receive the handle (void **) 0x10330404, which can be dereferenced to (void *) 0x10801000 (your 1024-byte long block).
At some point later on, you ask for a much larger allocation of 300KB. There isn't enough contiguous space to fulfil that, but wait-- if we relocate your 1024-byte block at 0x10801000 elsewhere, now we have 300KB to give you.
The OS quietly moves your 1024-byte block to 0x10653400, and writes that address to 0x10330404.
You didn't store the address of the block, you stored the address of the handle. The next time you want to access the block, you'll dereference (void **) 0x10330404, which now contains the new location of the block. Success!
There are various control functions that allow you to influence the behaviour of the memory manager. For example, you can use HLock and HUnlock to temporarily stop the OS from relocating specific blocks, in case you need to work with interior pointers directly.
There's enough RAM on modern systems that I haven't bothered implementing relocations into my emulator. It implements the Handle functions so that the guest application can allocate memory, but it will never actually relocate the block unless SetHandleSize is used to make it larger.
Executables
Mac OS supports two executable formats, XCOFF and the newer PEF (Preferred Executable Format). For the time being, I've only investigated and implemented PEF support.
PEF is a pretty straightforward format for both executables and shared libraries, so there's not really much to say about it.
Hopefully, this has given you enough of a background on the classic Mac OS to follow along with the next parts. It's time to write some code!
Writing a Disassembler
My first goal was to try and make sense of Mac executables, so I started with a trivial disassembler.
The PEF structure is documented by Apple's Inside Macintosh, which is kindly archived by the Wayback Machine. I threw together some Rust code using binread to parse the structures and print them out, so I had a better idea what I was dealing with.
The files I was looking at all followed a fairly straightforward template.
- Section 0: Code
- Contains all the PowerPC instructions, and some debugging structures directly following functions
- Ghidra calls them 'PEF_Debug', CodeWarrior's dumping tool calls them 'traceback tables'
- Section 1: Data
- Contains the Table of Contents (pointers to all data used)
- Contains all constant data
- Contains placeholders for all global data
- No distinction is made between any of these, they're lumped into the same block
- Encoded using a rudimentary compression format called 'pattern-initialised data'
- Section 2: Loader
- Contains the entry point and initialisation/termination function addresses
- Contains info about imported symbols and libraries
- Contains a hash table of exported symbols
- Contains relocations
Table of Contents
The TOC is the most interesting part of the PowerPC Mac ABI. Consider this dilemma...
PowerPC instructions are a fixed 32 bits. Loading a 32-bit address into a register therefore requires two instructions.
lis r3, 0x8042 # set r3 to 0x8042 << 16
ori r3, r3, 0xF980 # r3 = r3 | 0xF980This takes extra space and also requires more relocations, as each and every load must be adjusted when the executable is loaded into memory.
This is where the TOC comes in, as an index of all addresses required by the executable. Register 2 (sometimes called rtoc) is always a pointer to a specific location in the Data section.
PowerPC's load and store instructions allow you to specify a location by using a register and a signed 16-bit offset. Hence, if rtoc is set to 0x8042F980 and you want to read the pointer stored at 0x8042F878, you can use the instruction lwz r3, -0x108(r2) and do it easily.
Transition Vectors and Glue Functions
Assuming that r2 always points to the same location is all well and good inside your executable, but what do you do if you need to call a function from a different library - which almost certainly has a different TOC?
Code is addressed using what's called a transition vector. This is just a tiny structure that contains an address to the code and the address of that code's TOC.
The linker generates glue functions which are tiny helpers for this purpose. Here's what happens, with annotations for those of you who aren't as familiar with PowerPC assembly.
# calling an imported function ('GetDateTime')
bl GetDateTime # call the glue function
lwz r2, 0x14(r1) # reload rtoc from a fixed location on the stack
# ... (more stuff) ...
GetDateTime:
lwz r12, -0x7ED4(r2) # load a pointer to the transition vector from the TOC, into r12
stw r2, 0x14(r1) # save our current rtoc to the stack
lwz r0, 0(r12) # load a pointer to GetDateTime's code into r0
lwz r2, 4(r12) # load GetDateTime's rtoc value
mtctr r0 # move the code pointer from r0 into the special CTR register
bctr # jump to the CTR register (without updating the return address)It saves the current TOC address to the stack, switches to the target function's TOC, calls it, and then reloads it.
Note that the lwz r2, 0x14(r1) instruction must be in the calling function and cannot be in the glue function. This is because the glue function performs a tail call (jumps straight to the target function).
Performing any extra operations in the glue function would require it to set up a stack frame so that it can save LR (the return address) and that would have a performance impact, so on the whole it makes more sense to just take the one-instruction penalty after each call.
Relocations
The PEF loader section can contain multiple relocation blocks, applied to different sections - but so far I've only seen files that contain one block, applied to the data section.
Relocations are stored as a stream of commands which are executed in order. I won't go into detail here (you can read the official docs if you're really curious), but a typical stream looks like this.
- Write pointers to 12 imported symbols
- Write pointer to imported symbol 13
- Write pointers to 4 imported symbols
- Skip 36 bytes and add the data section's base address to 4 consecutive pointers
- Add the code section's base address to 17 consecutive pointers
Most commands support a repeat count, and it even has a command which allows you to repeat a whole group of commands a specific amount of times. It's clearly optimised for space.
Verifying my Code
I had been analysing Mac executables using Ghidra, but it does some post-processing on PEF files and it wasn't clear to me what was part of the file and what was added by Ghidra.
I ended up implementing a simple disassembler using capstone-rs which would take a PEF and spit out assembly, complete with labels for code/data references.
One neat trick is that since these binaries conform strictly to certain rules (e.g. always accessing pointers through the TOC), it makes it really easy to discover references which would normally require a certain level of code analysis.
After I'd gotten that working, I decided to take what I'd written and pivot into writing an emulator.
$ cargo new mpw-emu
Writing an Emulator
The obvious choice to start with here is Unicorn Engine, which is essentially the CPU emulator from QEMU made into an embeddable library. I've used it for a bunch of projects before. They've brought Rust bindings into the tree now which is also quite cool!
Bare Minimum
I started by taking the PEF loading code I'd written for my disassembler and reworking it so that it would "link" the executable into a byte array, with a fixed load address at 0x10000000.
The process is pretty simple:
- Map some address space for the executable, and load in the results of my linker
- Map some address space for dynamically allocated memory and for the stack
- Set the stack pointer
- Set the program counter and TOC pointer (using the entry point specified by the PEF)
- Start the emulator
Well, mostly. I've glossed over one important aspect here, which is libraries. A fully-fledged Mac emulator would load these from Mac OS, and the linker would just match up all the transition vectors with the corresponding functions from libraries. We're not doing that, so we need some way to implement their behaviour.
Hooking Imports
The glue functions in the code I'm emulating will automatically jump to a particular transition vector (a pair of values holding a code address and a TOC pointer) for each function. The challenge is... how do I make my own code run when this occurs?
Unicorn has various hooks where you can set a callback to be executed when a specific event occurs. One of them is "interrupt", which for PowerPC is linked to the sc (Supervisor Call) instruction. If I make the emulator execute sc, then I can do something special.
I allocated some space for a tiny function which just executes sc and then returns. I can then insert that into the imported functions' transition vectors. There's a TOC pointer I don't need, but I can use that as a bit of information that tells me which function was executed.
for (i, sym) in loader.imported_symbols.iter().enumerate() {
match sym.class {
pef::SymbolClass::TVect => {
let shim = self.allocate_memory(8);
self.set_u32(shim, sc_thunk);
self.set_u32(shim + 4, i as u32);
self.shim_addrs.push(shim);
}
pef::SymbolClass::Data => {
let shim = self.allocate_memory(1024);
self.shim_addrs.push(shim);
}
_ => panic!()
}
}I ended up with this logic. Pointers to functions receive this fake transition vector that contains the imported symbol's index as the TOC pointer, and pointers to data receive a 1024-byte placeholder block.
fn intr_hook(uc: &mut EmuUC, _number: u32) {
let rtoc = uc.reg_read(RegisterPPC::GPR2).unwrap();
let lr = uc.reg_read(74).unwrap();
let pc = uc.pc_read().unwrap();
let state = Rc::clone(uc.get_data());
let mut state = state.borrow_mut();
if state.exit_status.is_some() {
// we have exited, go away
// (unicorn keeps running code afterwards)
uc.emu_stop().unwrap();
return;
}
match state.imports[rtoc as usize].func {
Some(func) => {
let mut arg_reader = helpers::ArgReader::new();
match func(uc, &mut state, &mut arg_reader) {
Ok(Some(result)) => uc.reg_write(RegisterPPC::GPR3, result.into()).unwrap(),
Ok(None) => {},
Err(e) => {
error!(target: "emulator", "Error {e:?} while executing {} (lr={lr:08x})", state.imports[rtoc as usize].name);
}
}
}
None => {
warn!(target: "emulator", "Unimplemented call to {} @{lr:08X}", state.imports[rtoc as usize].name);
}
}
// NOTE: next unicorn will not need this i think?
uc.set_pc(pc + 4).unwrap();
}The plan works! Whenever the emulator calls a library function, it loads the function's index into rtoc (r2) and invokes sc. Then, my hook looks at r2 to determine which function we should try and simulate.
Floating Point
I got a strange failure early on which didn't make sense. After looking at the relevant code in Ghidra, the problem became obvious - the emulator didn't know how to execute floating point instructions.
The FPU is turned off by default. The fix was simple - set the corresponding bit in the MSR (machine state register).
// enable floating point
uc.reg_write(77, uc.reg_read(77)? | (1 << 13))?;With that, we're ready to go.
Bringing up Libraries
The CodeWarrior C/C++ compiler (MWCPPC) imports over a hundred library functions, but I didn't want to just implement every single one right off the bat - I wanted to see results faster than that, so I ran it and implemented things as they came up.
Passing command line arguments required me to feed it the typical argc and argv, which in MPW land seem to be fetched from an imported data symbol called _IntEnv. I wrote some code to pass the arguments through and store them in the right location, and that made the compiler happy enough to print out some error messages. Progress!
C Library
I had to implement a decent amount of C standard library functions. For the most part, this isn't too big a deal. They're well-defined and well-documented, and most of the ones used in MWCPPC are quite simple.
At one point I had the compiler running and spitting out object files, but they didn't seem to be correct; they included code but no strings or names. It would also crash if I added a virtual method. After a few hours of frustration, I realised MWCPPC has an -e parameter which runs the preprocessor and spits out the resulting output. I tried it and got this result:
(); { : ~() { } }; [] = "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"; ( , ) { (); ( * ) + ; } ( *) { ( = ; < ; ) { [] []; } }Oops? I wondered what could be going wrong here, so I had a look at my library functions instead... and realised that I'd screwed up memcpy and it wasn't actually copying. Fixing that made everything work!
The most painful part of the C library to deal with was definitely printf. There are a couple of Rust crates that implement C-ish printf, but neither would have worked for me due to my constraints.
One implements printf with a variadic API, like the real C version. The other one accepts a slice of types, but you're expected to know what they are beforehand.
I have no way to build up a list of arguments without actually processing the format string, and there's one big thing that makes this tricky with PowerPC: floating point values are stored in a separate set of registers. I cannot tell the difference between func(1.0, 100) and func(100, 1.0) as in both cases, r3 will contain 100 and fp1 will contain 1.0.
I ended up implementing my own, which doesn't currently include every part of the standard feature set, but does enough to run MWCPPC correctly.
Macintosh Toolbox
The largest chunk of the work here is certainly in implementing the Toolbox APIs. I mainly need to be concerned with resources, memory management and file management. I went into detail earlier in this post about these three features, but I haven't really explained how I emulated them.
There's a number of function calls I can either ignore entirely, or simply return static values from.
MWCPPC makes calls to functions in QuickDraw (graphics API) to set up graphics state and set the mouse cursor, but these don't actually matter to us.
There's also the Gestalt, which is a mechanism by which applications can get info about the system. There is a wide variety of 'selectors', ranging from the AppleTalk version number to the amount of NuBus slots present. Thankfully we can ignore most of them and just implement the ones that MWCPPC asks for.
I tell it that we have an alias manager, no special OS features, and no support for FindFolder. Skipping the latter two saves me some work, but it does get me the warning "-mf ignored since your system doesn't support Real Temp Memory".
Resources
Toolbox exposes APIs for manipulating resources, but MWCPPC doesn't need most of them which is lucky. I can get away with just implementing GetResource and Get1Resource, which return a handle containing the resource's data.
I parse the executable's resources and load them into a Rust structure on startup (memory is way cheaper in 2022 than in the 1990s after all!), and I also have a HashMap<(FourCC, i16), u32> storing which resources have already been loaded into the emulated memory.
When a resource is requested, I check the map to see if it's already loaded. If not, I allocate a new handle and copy the resource's data to that handle.
Memory Management
This is a necessity for anything non-trivial. My first shot at the emulator didn't actually support freeing memory, I would just increment a pointer every time an allocation was performed. It worked OK, but I knew I would need something a little more robust so I sunk some time into writing a minimal memory manager.
What I came up with is not really optimal, but it's reasonably simple and that fits the bill here.
I allocate a fixed amount of address space (currently 8MB) towards dynamic allocations. I reserve a little space at the beginning for handles, and then the rest is split into blocks which are connected in a linked list.
At the start, the entire region is covered by one large block of free space. Each block has a 16-byte header with information.
| Offset | Name | Purpose |
|---|---|---|
| 0 | User Size | Size of the user-requested allocation, or 0x80000000 if the block is free |
| 4 | Block Size | Size of this block, including header |
| 8 | Prev | Pointer to the previous block, or 0 |
| 12 | Next | Pointer to the next block, or 0 |
There are four core operations that I need to support.
NewPtr/NewHandle
I scan the list of blocks, starting at the end, looking for the first block which is free and able to hold the requested allocation (rounded up to 16 bytes).
Once a suitable block is found, I compare its size to the requested allocation. If there's at least 32 bytes left over, then I split the block in two, creating a used block (just big enough to hold the allocation) and a free block (with the remaining space). If not, I simply mark the entire block as used.
DisposePtr/DisposeHandle
I subtract 16 from the pointer to get the address of the allocation block, and then mark it as free.
If the next block after it is free, then I merge it into the disposed block, creating one large big block.
If the previous block before it is free, then I merge it into the disposed block, creating one large big block.
This means that two free blocks should never appear consecutively in the list (as they'll be merged together by the Dispose operation), which simplifies the process of finding an appropriate free block when allocating memory.
GetPtrSize/GetHandleSize
This one is straightforward. I subtract 16 from the pointer to get the address of the allocation block, and then return the user size from it.
SetPtrSize
Block resizing is trickier, and I was worried about screwing it up. I managed to implement both of these operations using the methods I'd already built, which I was quite pleased with.
SetPtrSize allows you to make a block smaller, and possibly allows you to make it larger, but this can fail as there may not be enough space directly following it.
- If the next block is free, then merge it with the block that's being resized
- This grows the block to its maximum size, up to either the next used block or the end of the heap
- If the block has enough space to fit the desired size, then change its user size to match
- If the new user size is larger than the old size, fill the extra space with null bytes
- Regardless of whether it succeeded or not, split the block into a used + free pair again
This elegantly handles both growing and shrinking the allocation. In either case, the resulting state will contain a used block that's only as big as necessary, and a free block with any leftover space.
SetHandleSize
SetHandleSize always allows you to resize a block - handles are relocatable, so the OS can simply allocate a new contiguous block and move your data over if necessary.
I first try to use SetPtrSize to resize the backing buffer to the requested size. If this doesn't work, I allocate a new backing buffer, update the handle to point to it, move the data over and then free the old buffer.
Other Nonsense
The Mac OS memory subsystem supports a bunch of other stuff, like the ability to lock a handle so that the OS won't relocate its backing buffer, but I haven't implemented any of it.
If I run into memory issues, I can expand the heap size, or possibly even add the ability to dynamically grow it. I'm keeping it simple for now though as this may just not be necessary at all for my use cases.
File Management
As I explained in an earlier part of this article, file management is where classic Mac OS is just completely out of touch with every other OS. This makes it an interesting challenge to try and give the guest application access to files.
Files and directories are accessed using an object called FSSpec, which contains a volume ID, a directory ID and the name of the file/directory. There's no absolute path to a file, because Mac OS doesn't want you to do that.
There's also multiple different kinds of file system APIs that operate at different levels of abstraction. The documentation is littered with warnings which quite frankly terrify me.
HOpen: If you use
HOpento try to open a file whose name begins with a period, you might mistakenly open a driver instead; subsequent attempts to write data might corrupt data on the target device. To avoid these problems, you should always useHOpenDFinstead ofHOpen.FSClose: Make sure that you do not call
FSClosewith a file reference number of a file that has already been closed. Attempting to close the same file twice may result in loss of data on a volume. See "File Control Blocks" on page 2-81 for a description of how this can happen.
I ended up doing something rather hacky which I'm not all too happy with, but it's a compromise that I might revisit later.
I ignore volumes entirely, exposing everything as if it were part of the 'default volume' with ID 0. I assign IDs sequentially to directories whenever the guest application needs to learn about a directory.
I implemented enough of the functions to make MWCPPC run and generate object files, but I'm almost certainly going to need to put more in later on.
At some point I might have to implement the functions that allow for iteration through a directory's contents, and that scares me a bit :p
Smoke Test
It works!
$ ./target/debug/mpw-emu MWCPPC.bin example.cp
### MWCPPC.bin Usage Warning:
# -mf ignored since your system doesn't support Real Temp Memory
### MWCPPC.bin Usage Warning:
# the environment variable 'MWCIncludes' is not setAt some point I'll hopefully get the disassembler to work too - I need to implement more junk for it. It currently chokes on me hardcoding the type ID of input files as TEXT, and if I change that, then it fails because it uses a different function for opening files that I haven't yet gotten to work.
$ RUST_LOG=debug ./target/debug/mpw-emu MWDumpPPC.bin example.cp.o
[2022-02-28T21:35:19Z DEBUG linker] Section: None Default=0 Size(Total=17460, Unpacked=17460, Packed=17460) Kind(Section=Code, Share=GlobalShare) Align=4
[2022-02-28T21:35:19Z DEBUG linker] Section: None Default=0 Size(Total=7B08, Unpacked=5FDC, Packed=4BCD) Kind(Section=PatternInitData, Share=ProcessShare) Align=4
[2022-02-28T21:35:19Z DEBUG linker] Section: None Default=0 Size(Total=0, Unpacked=0, Packed=5C4) Kind(Section=Loader, Share=GlobalShare) Align=4
[2022-02-28T21:35:19Z DEBUG stdlib] _IntEnv ptr is at: 1011F3D4
[2022-02-28T21:35:19Z DEBUG emulator] Main: code=10000218, rtoc=10017460
[2022-02-28T21:35:19Z WARN emulator] Unimplemented call to setvbuf @10006904
[2022-02-28T21:35:19Z INFO stdlib] signal(2, 10017D84)
[2022-02-28T21:35:19Z WARN emulator] Unimplemented call to TrapAvailable @100007B0
[2022-02-28T21:35:19Z WARN emulator] Unimplemented call to SetResLoad @1000035C
[2022-02-28T21:35:19Z WARN emulator] Unimplemented call to SetResLoad @1000041C
[2022-02-28T21:35:19Z WARN emulator] Unimplemented call to CurResFile @1000693C
[2022-02-28T21:35:19Z INFO files] MakeResolvedFSSpec(vol=0, dir=0, name="example.cp.o", spec=1011ECF8, ...)
[2022-02-28T21:35:19Z DEBUG fs] 10 => "/Users/ash/src/mpw-emu"
[2022-02-28T21:35:19Z INFO files] HCreate(vol=0, dir=10, name="example.cp.o")
[2022-02-28T21:35:19Z WARN emulator] Unimplemented call to CurResFile @100064DC
[2022-02-28T21:35:19Z WARN emulator] Unimplemented call to FSpOpenDF @100147F0
[2022-02-28T21:35:19Z INFO files] MakeResolvedFSSpec(vol=0, dir=0, name="SysErrs.Err", spec=1011EB1C, ...)
[2022-02-28T21:35:19Z INFO files] MakeResolvedFSSpec(vol=0, dir=0, name="SysErrs.Err", spec=1011EB1C, ...)
[2022-02-28T21:35:19Z INFO files] MakeResolvedFSSpec(vol=0, dir=0, name="SysErrs.Err", spec=1011EB1C, ...)
### MWDumpPPC.bin Linker Error:
# Can?t read library file ?example.cp.o?.
# OS error -4872 (Error message file not available)
[2022-02-28T21:35:19Z WARN emulator] Unimplemented call to UseResFile @10006648
# errors caused tool to abort
[2022-02-28T21:35:19Z INFO stdlib] exit(1)But hey, we're getting there!
I tend to write projects in a very experimental and messy fashion as I learn what I'm doing, and then I'll clean them up once I'm more familiar with the problem space.
I originally had all of my standard library functions in a single match block, but I've broken them out into individual functions and split them into files based on what C header they come from. I also created an ArgReader object which wraps argument parsing, making this whole business way more elegant.
Conclusion
Now that the codebase is less of a trash fire, I'd like to make more progress and run some of the other MPW tools. There's almost certainly more issues that will arise with MWCPPC that I haven't yet come across in my limited testing.
I still have my pipe dream of decompiling Yoot Tower, but that's a fairly hefty task so in all likelihood it won't actually happen. At least I've had some fun with this project...
Find the source code on GitHub here: https://github.com/Treeki/mpw-emu/
Previous Post: Reversing Games with... Hashcat???
Next Post: Joining the NixOS Pyramid Scheme